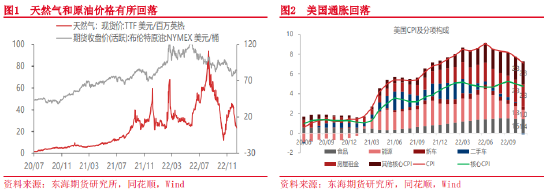
债券领域专用词向量研究
自然语言处理技术推动着智能债市的发展,其关键在于利用计算机充分挖掘债市数据中蕴含的特征和规律。这些特征的本质是对债市文本的数字化编码,可作为债市文本分类、债市舆情分析、债券智能问答等多种应用的计算机输入“语言”,是实现智能债市的基础。为了实现对债市文本特征的预提取,本文利用CBOW模型对大量债市文本进行训练,获得了首套债市领域专用的数字“词典”,填补了债券领域专用词向量的空白。该词向量利用文本的上下文信息,已经具备了一定的语义表达能力,不仅可以区分一字多义,还可以针对特定概念群进行类推。
债券市场是金融市场的重要组成部分。债券的全生命周期中会产生海量的文本数据,其中蕴含着债券市场大量的知识和规律。然而,这也导致了债券市场大数据的知识体系较为庞杂,且数据中一些冗余、错误和有用信息混杂交错,需要进行整合、清洗和挖掘来获取有用的信息。仅依赖人工处理难度较大,也是对社会资源的极大浪费。依靠债券领域得天独厚的数据优势,自然语言处理(NLP)技术具备模型端到端的设计和对特征工程弱依赖的特点,已成为赋能债券领域各应用的强大助力,带动着金融业逐步迈入智能金融新纪元。
目前,NLP技术正广泛应用于智能客服、定制化推荐、自动文摘、舆情分析、文档分类等债市服务中。然而,这些应用的实现往往取决于债市文本数据和特征质量。在运用NLP技术对特征进行自动化提取的过程中,债市文本作为非结构化的字符数据,无法直接被计算机识别,需要转化为具有语义信息的数值形式。具体地,需要将由多个词构成的文本空间转化为高维向量空间,即利用向量表示词,向量之间的距离刻画词与词之间的相近程度,最终形成“文本-词”的债市数字词典(词向量)。
本文为填补债市专用词向量的空白,利用词向量训练技术,以债市特定文本作为训练语料库,训练出一套富含债市领域先验知识的数字词典。该词向量区别于传统关键词、规则匹配,已经具备一定的语义表达能力。
词向量编码方式选择
词向量本质是以词为单位,用多个数值对文本进行编码,编码方式主要包括独热(one-hot)、共现矩阵和分布式编码等,具体描述如表1所示。
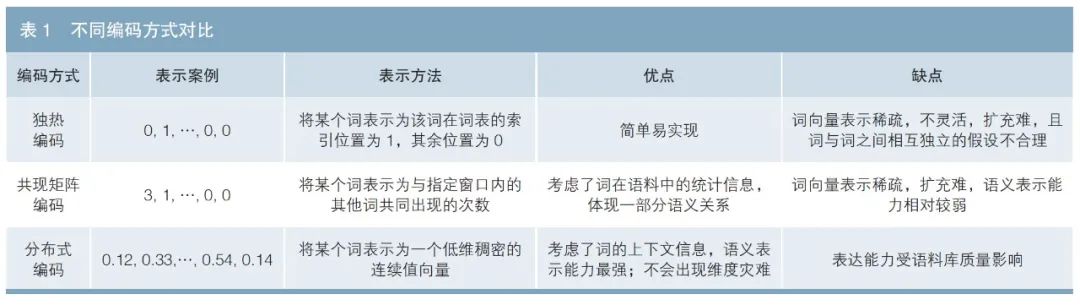
目前较为流行的词向量编码方式为分布式编码,该种编码的优点在于:第一,通过度量向量之间的相似程度,词之间具备了“距离”的概念,这对很多NLP的下游任务(文档分类、命名实体识别、情感分析、问答系统等)极有意义。第二,该词向量的每一维都有特定的含义,同等维度的词向量,该词向量能包含更多的语义信息。因此,该词向量可以节省更多的存储空间,并提高计算效率。区别于离散编码,分布式编码在扩增新词汇时无需增大向量维度,所构成的语义矩阵不再稀疏,不会出现维度灾难。因此,本文所研究的词向量基于分布式编码。
词向量训练
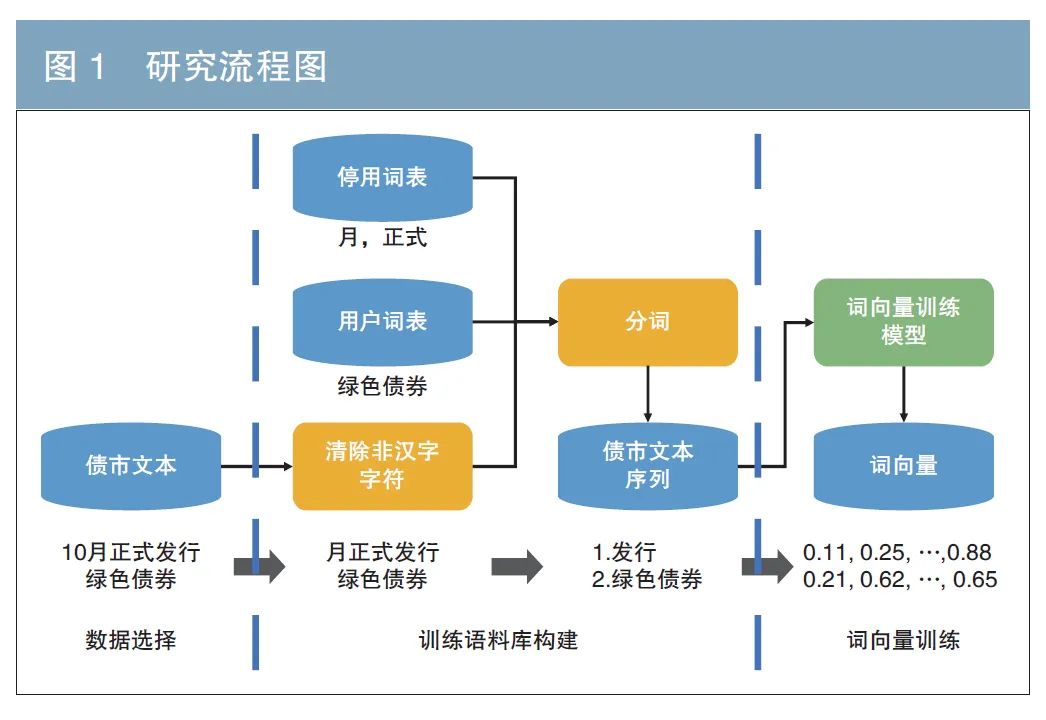
本研究的详细流程见图1,主要分为债市文本数据选择、训练语料库构建及训练模型和对应的参数设置。
(一)债市文本数据选择
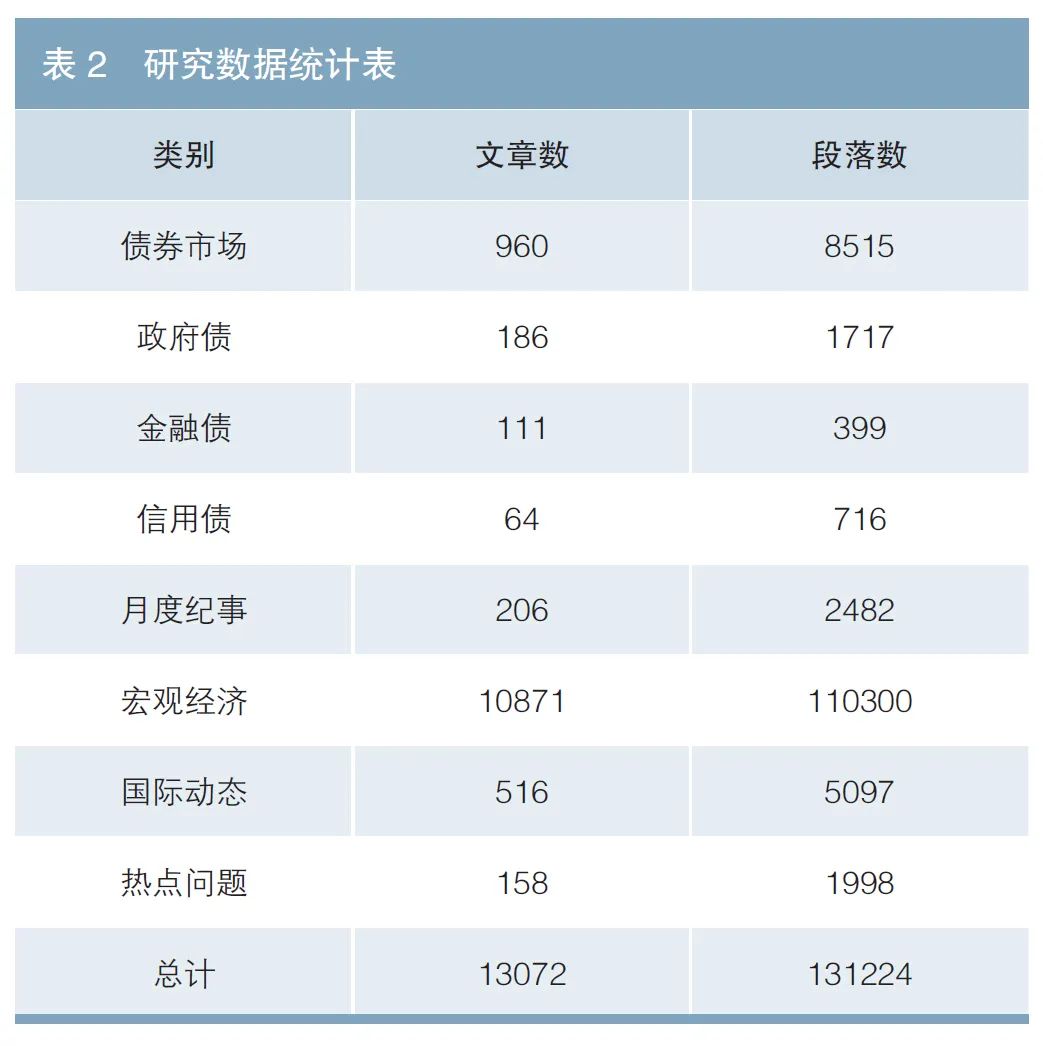
本研究所使用的数据来源为:截至2022年2月23日中国债券信息网(https://www.chinabond.com.cn/)的公开文本,主要涉及该网站的8个子栏目:债券市场、政府债券、金融债、信用债、月度纪事、宏观经济、国际动态和热点问题。该网站披露的数据均经过领域内专家筛选,质量可靠且覆盖面较广,共计13702篇文章,131224个自然段落,具体统计信息如表2所示。
(二)训练语料库构建
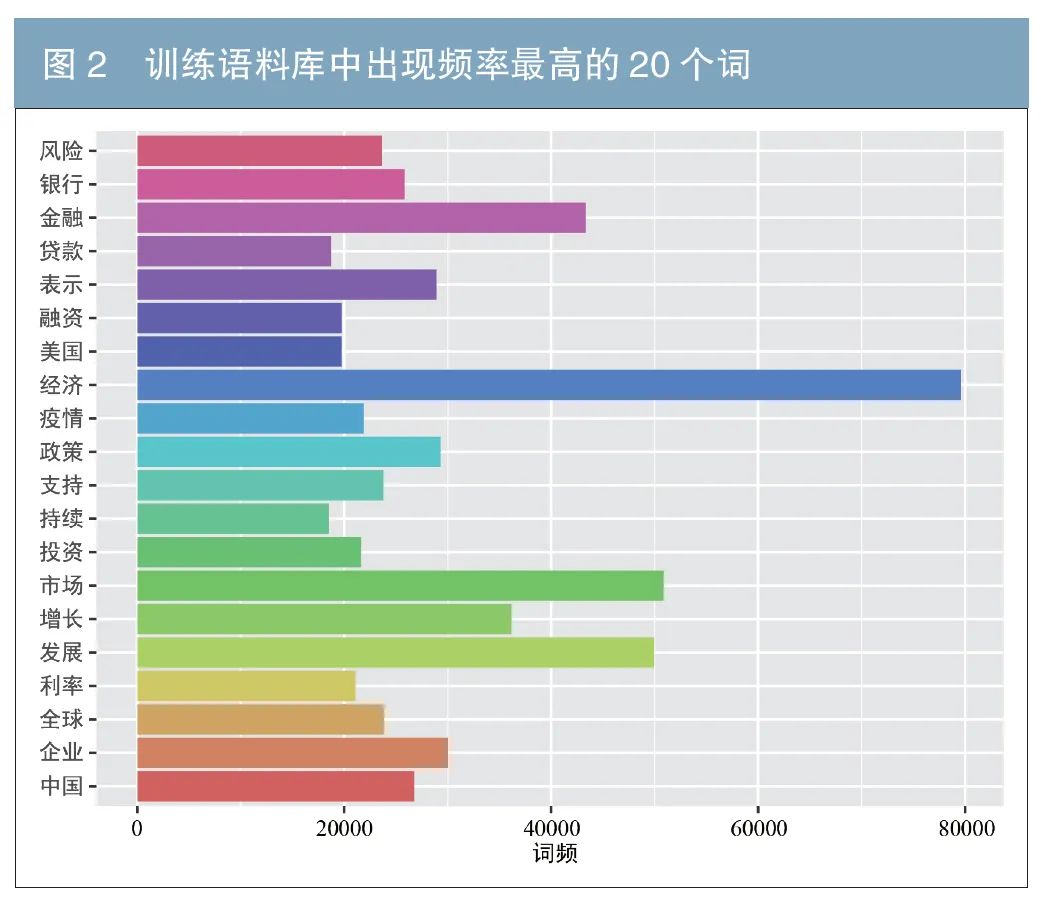
本文预训练语料库的构建分为两步:第一步,清除文章中所有非汉字成分,主要包括标点符号、字母等。第二步,利用“结巴”(jieba)工具对文本进行分词得到债市文本序列。其中,分词需要配备有停用词表(可忽略的不影响语义的词)和用户词表(领域内的默认专用词)。例如,文本“10月正式发行绿色债券”,清除非汉字字符后得到“月正式发行绿色债券”,去除停用词“月”“正式”,保留用户词“绿色债券”,经分词所得的债市文本序列为:“发行”“绿色债券”(见图1)。原文本中每个段落所得的债市文本序列集合构成了词向量训练的语料库,图2与图3分别展示了语料库中最频繁出现的前20和200个词。

(三)训练模型及其参数设置
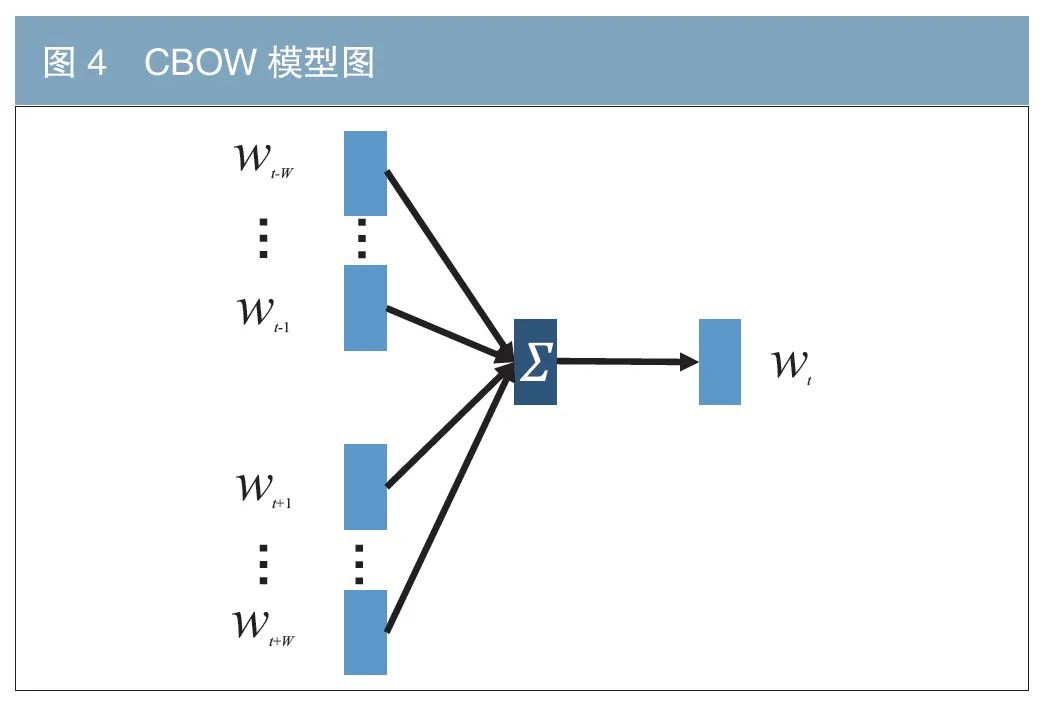
本文使用的词向量训练模型为连续词袋模型(Continuous Bag Of Words,CBOW),该方法利用目标词的上下文词表示该词(见图4)。具体地,训练语料库记为D,词表集合记作W=(w1,w2,…,wN),N为词数目。词袋中任意一个词wi的输入和输出向量分别记作VWi和V^Wio。模型的目标函数(最大化对数似然函数)可定义为:
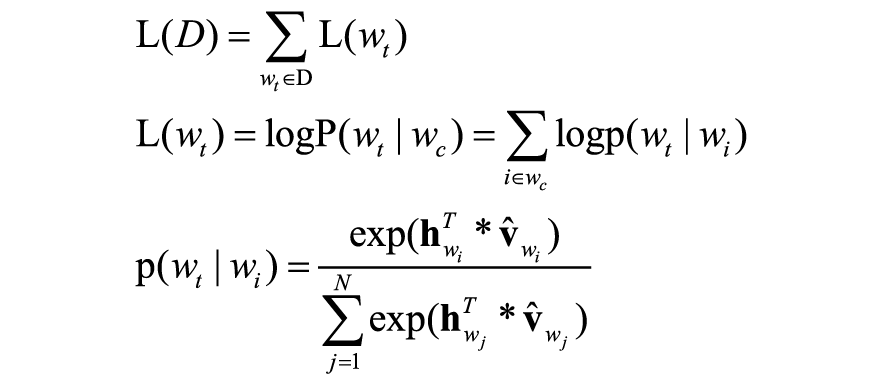
其中,wc=wt-W,…,wt-1,wt 1,…,wt W代表目标词wt的上下文词,W为上下文窗口的大小。hwi代表目标词上下文词向量的均值或和向量。由于每次梯度迭代更新时,需涉及所有词向量,复杂度较高。为了加速模型计算,本文采用了负采样算法进行优化,即将每个目标词的上下文词作为正样本,对每个正样本采样多个负样本,每次梯度更新仅涉及所有的正负样本词。本文对每个正样本所采样的负样本为10,具体实现可参考文献。此外,本文过滤了词典中出现次数小于5的词,设置词向量的维度为200,上下文窗口为5,训练的轮次为100,初始学习率为0.025。
训练结果分析
(一)语义表达能力
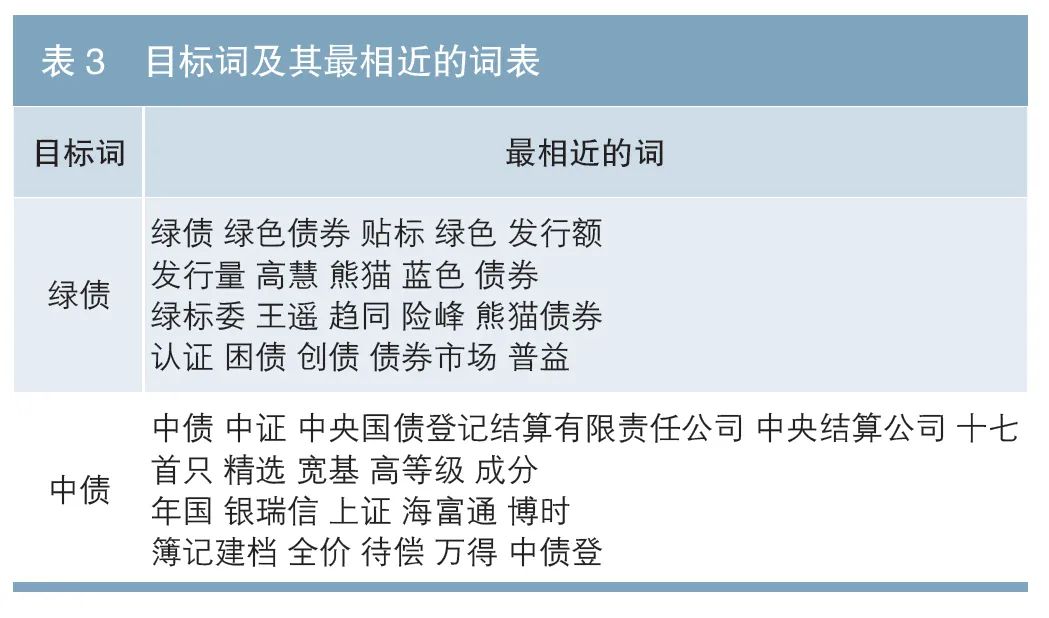
本文通过词向量之间的皮尔斯相关系数来刻画词之间的相似程度,以衡量本文词向量的语义表达能力。表3以“绿债”“中债”为例,展示了与之最相关的词。其中,与“绿债”语义最相近的词语包括“绿色债券”“绿色”“债券”“绿标委”等与“绿债”有重叠字的词,还包括“贴标”“蓝色(债券)”“熊猫(债券)”等字面上不相关的词。对于“中债”,虽然汉语中含有“中”“债”的词很多,但是与之最相近的前3个词仅包括“中证”“中央国债登记结算有限责任公司”“中央结算公司”。由于训练过程中并未加入任何人工规则,这些结果表明该词向量已经可以自动捕捉到债市语料所蕴含的特征和规律,并将该特征存于数值向量中。不同于关键词匹配的语义识别,该词向量已经在文本的语义层面具备一定的理解能力。
(二)区分一字多义的能力
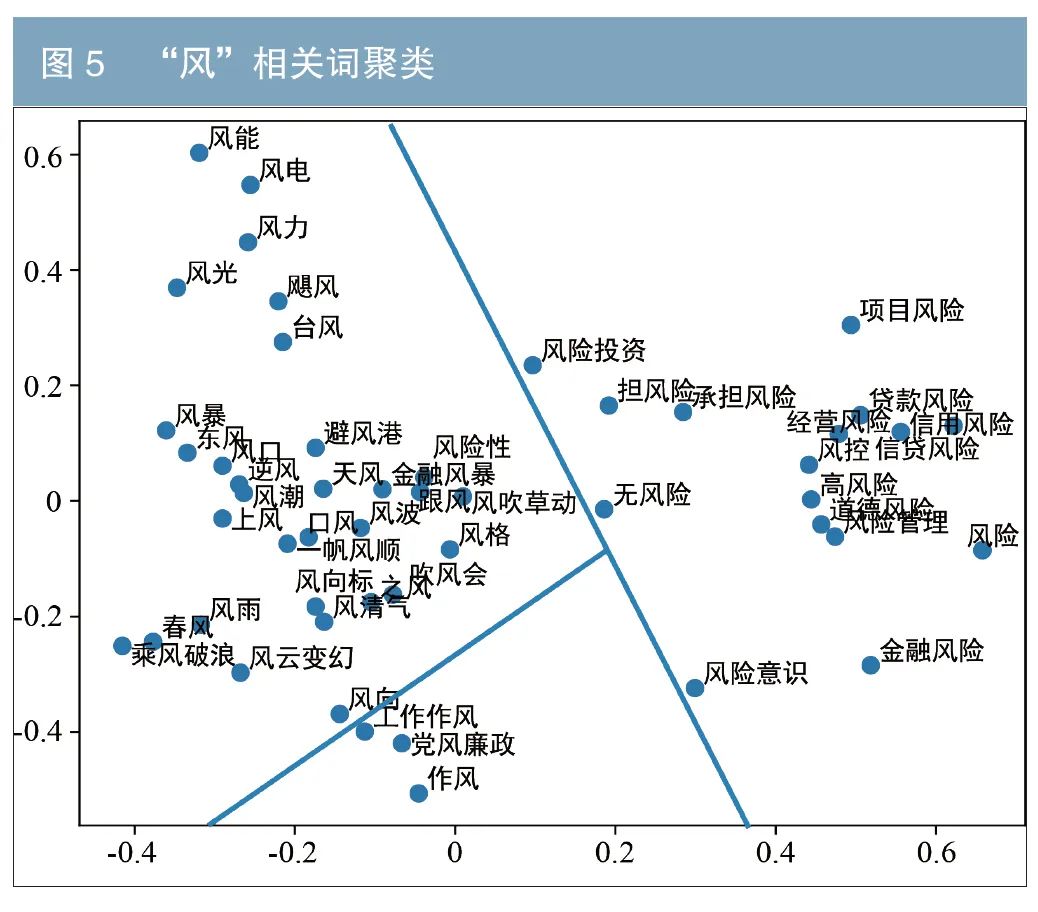
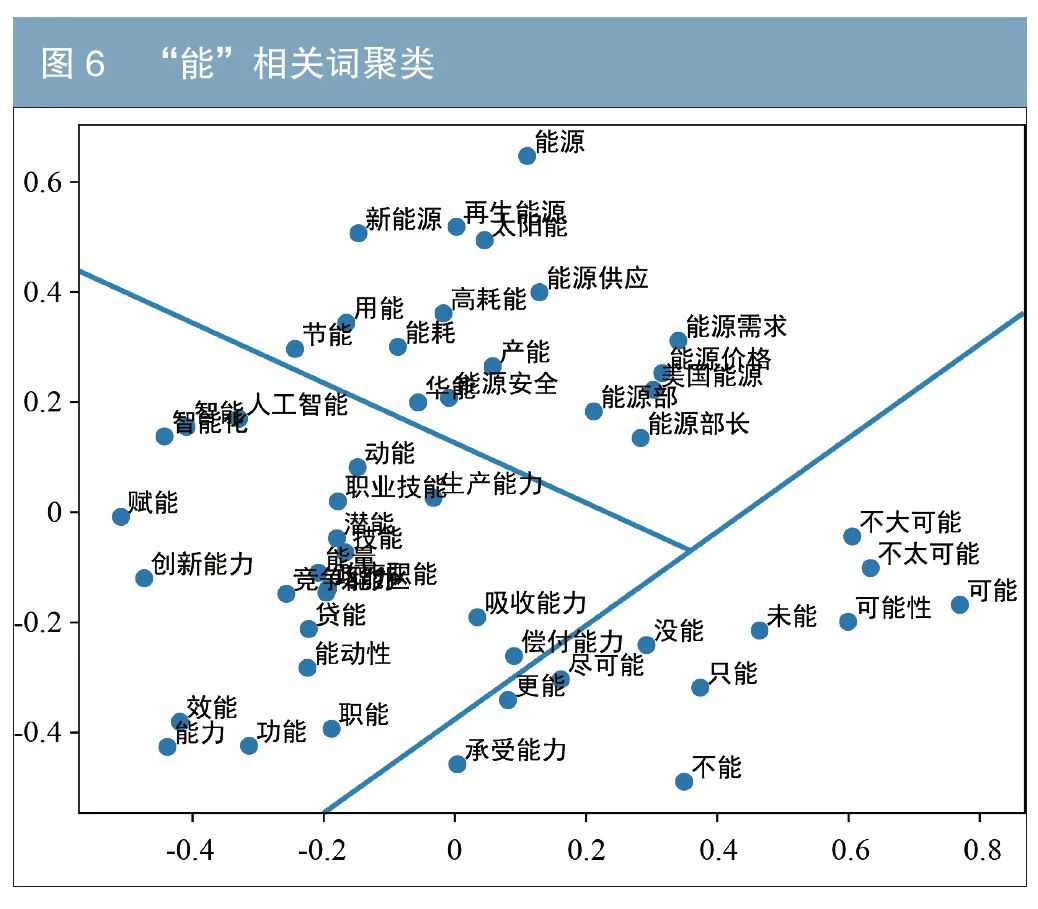
中文存在着大量的多义字,比如“风”可以指具象的自然界的空气流动现象(风速)、消息(闻风而动)、歌谣(国风),或抽象的社会长期形成的礼节(风气)、外在表现的态度和举止(风度)等。为阐述本研究词向量区分一字多义的能力,笔者分别展示了带有“风”和“能”的前50个词,并进行个案分析。具体地,首先对这些词对应的向量进行主成分分析(PCA),然后对结果的前2个主成分进行可视化。图5中“风”主要分成3类:自然界的风、风险和作风相关的语义。图6中“能”被分为:能力、能源和虚词能相关的语义。该结果揭示了该词向量保留了词之间的语义关系,即相近字义的词在向量空间上也是临近的,一定程度上可以区分一字多义。
(三)类推能力
本文选取了4对不同的债券类型和对应的发行主体,并对这8个词向量进行PCA降维,选择前2个主成分进行可视化。
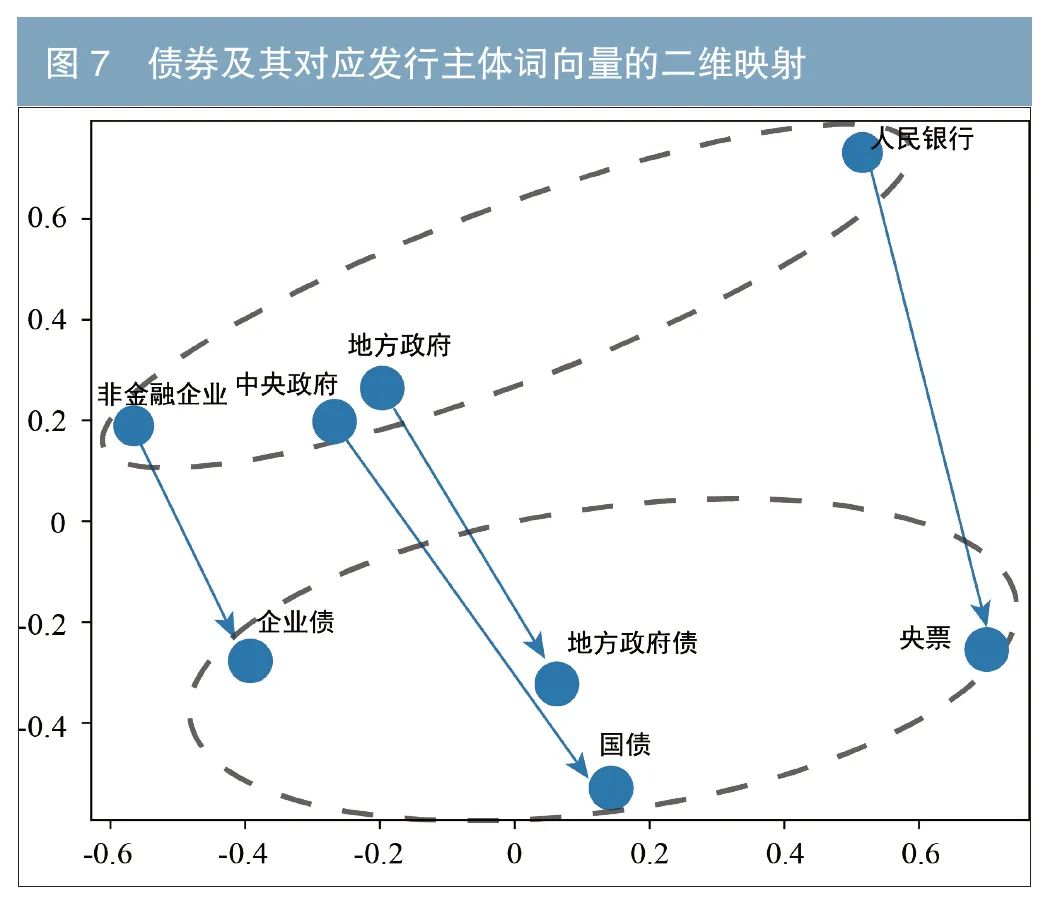
如图7所示,结果发现发行主体和债券类型被分为两类(虚线圈),位于图的两侧。此外,箭头的指向表明,债券发行主体和对应债券类型在图中的位置关系与其概念关系保持一致。尤其是地方政府和中央政府之间的距离比其他发行主体近,对应的两种债券类型也比其他债券类型近。由于训练过程中并未加入债券和对应的发行主体之间的概念关系或相关先验知识,该结果表明本研究的词向量能够自动组织概念,并学习概念之间的抽象关系进行类推。
结论
本研究利用CBOW模型对中国债券信息网中的13000多篇债市文本进行训练,并获得了首套债市领域专用的数字“词典”,填补了债券领域专用词向量的空白。该“词典”共有76042个债市专用词,每个词由200维向量组成,其内容涵盖了债券市场的各个子领域。不同于关键词匹配,该词向量能够区分一字多义,且可以针对特定概念群进行类推,已经具备了一定的语义表达能力。
当然,本研究中出现了一些错误的结果:一是分词导致的错误,比如“创债”“年国”等;二是一些无意义的词没有过滤,比如“首只”“十七”等;三是一些噪声词干扰词向量的训练,比如与“中债”最相近的词“精选”“高等级”“成分”等。为了解决这些问题,后续将尝试更多成熟的分词工具,并根据债市数据特点设计更多的用户专用词表和停用词表。此外,后续会补充更多的债券信息来源,以扩充词向量的训练语料库,训练出一个语义表达能力更强的债券领域专用词向量。
参考文献
[1]陈德光,马金林,马自萍,等. 自然语言处理预训练技术综述[J]. 计算机科学与探索,2021,15(8).
[2] Mikolov T, Sutskever I, Chen K et. al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013(26).
本文原载《债券》2022年12月刊
◇ 作者:中央结算公司博士后科研工作站 华娇娇
中央结算公司博士后科研工作站 杜通
中债金科信息技术有限公司 唐华云
◇ 编辑:鹿宁宁 廖雯雯
责任编辑:赵思远
【新浪教育】赵新:适合自己孩子的才是最好的
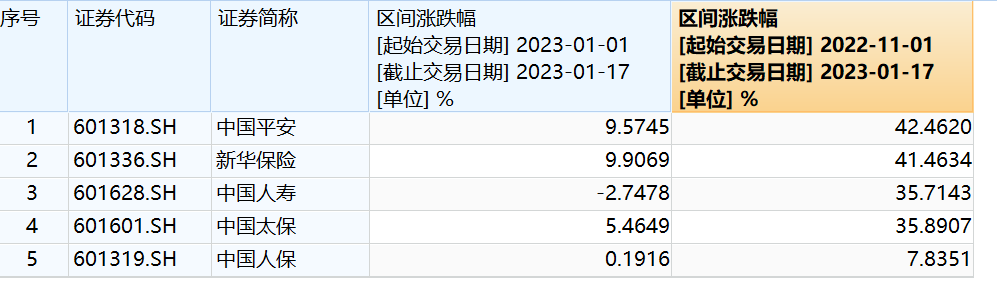
哈罗北京助理校长赵新做了《学贯中西,着眼未来》的主题分享,用多样实例,阐释了如何在现今教育环境下为孩子选择一所最适合的学校。随着国家经济的发展和国际地位的提升,全球化进程的加快,各行各业对人才的需要也发生了很大的变化。教育要跟随社会的发展和变迁,服务于社会。教育行业近10年发生了巨大的变化,家长有更多地选择权和选择空间。新浪财经2022-12-16 06:55:570000合计近2.56万亿元!A股五大险企重要数据出炉
转自:中国证券报截至1月17日,五大A股上市险企负债端重要年度数据保费收入全部披露完毕。中国平安、中国人保、中国人寿、中国太保、新华保险五家险企2022年实现原保险保费收入共近2.56万亿元,较此前一年增长2.9%。业内人士表示,虽然各家保费增长情况分化较大,但改善趋势已形成。展望2023年,保险资产、负债两端改善有望贯穿全年,板块估值修复仍有空间。共揽保费近2.56万亿元中证报2023-01-17 22:34:480000央行:2022年12月常备借贷便利开展情况
转自:货币政策司为满足金融机构临时性流动性需求,2022年12月,人民银行对金融机构开展常备借贷便利操作共124.40亿元,其中隔夜期5.00亿元,7天期113.40亿元,1个月期6.00亿元。期末常备借贷便利余额为123.00亿元。常备借贷便利利率发挥了利率走廊上限的作用,有利于维护货币市场利率平稳运行。隔夜、7天、1个月常备借贷便利利率分别为2.85%、3.00%、3.35%。 100002023-01-03 17:59:360000
100002023-01-03 17:59:360000